In industry, the recommendation systems are usually composed by two phases: candidate generation, and ranking, in order to satisfy the computational performance requirement. The method “DNN for YouTube Rec” proposed by youtube in 2016 RecSys conference introduces a model based on DNN that can be used for both candidate generation and ranking.
Candidate generation framework
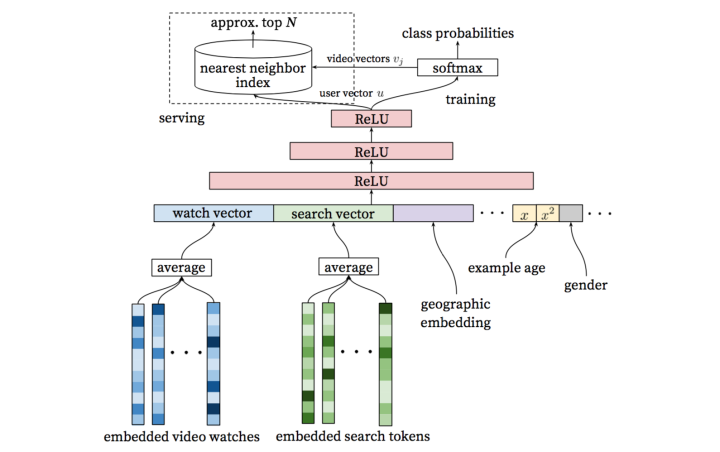
The model shown above produces user vectors and video vectors. During serving, the candidates are generated by finding nearest videos w.r.t. the inner product of user vector and video vector. Locality sensitive hashing may not suit the inner product well, other ANN (approximate nearest neighbor) methods such as the FAISS and hnswlib may work much better.
The formulae for softmax in the diagram is
where , represents the user feature and context, is the user embedding vector provided by , is the video embedding vector.
So the user vector is the output of the last hidden layer of the DNN, while the video vector is the weights of the softmax. The softmax can be viewed as the generalized matrix factorization, where computes the probability of video given user. Suppose the dimension of the output of the last hidden layer is , and there are million videos, then the dimension of the fully connected network for the softmax is , and the weight vector of dimension for each output node corresponds to the vector of that video.
In serving, we put the user features and context features to the network to compute the user vector, and then find the nearest videos via ANN services with video vectors indexed.
Ranking
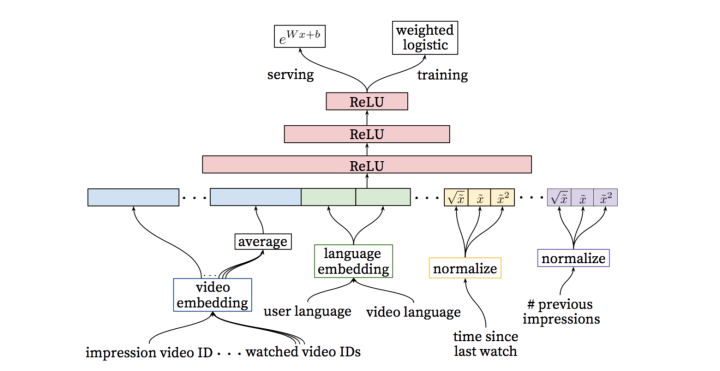
In ranking, the output layer is a weighted logistic regression during training, and an exponential function during serving. The model is built for predicting the expected watch time for each video for each user.
The weighted odds is , where is the total number of samples, is the number of positive samples, is the watch time for -th positive sample. With some transformation, we have
For logistic regression, we have
For the weighted logistic regression in the model, we have similarly
So the result in the serving is the prediction of the watch time. It is some what like some kind of calibration which perserves both the ordering and the distance. Not using regression directly may due to the robustness and the stability.
In order to optimise weighted LR, there exist two methods
- Up-sampling the positive samples according to their weights
- Magnify the gradient by sample weight during gradient descent
Tips from practical experience
-
Negative sampling
Similar to the training of large scale classification problems such as Word2vec or Item2vec, the negative sampling is used to increase the learning efficiency.
-
Example age
Use example age in training and use in serving, so as to encourage recommending fresh content. Here the example age refers to the time duration between sample log time and current instant time or to the time duration between sample log time and maximum sample log time in training data.
-
Down-sampling active user examples
This is to prevent a small cohort of highly active users from dominating the loss.
-
Use the latest action as the test example
This is to avoid time shuttle.
-
Use vector for embedding vector of long tailed videos
This is a trade-off to save computation resources in serving.
-
Some useful features
temperal features, negative actions, candiate source, score of scource, …
-
Normalizing
use the percentile of the value as the normalized value, square root of the normalized value, and the squared normalized value
One last important note, according to someone previously worked in youtube, the video embedding used for the input is not end-to-end trained from the network but generated by some other pre-trained model.
